马斯克Grok-4卖货创收碾压GPT-5,AI卖货排行榜曝光,AGI的尽头是卖薯片?
AGI的尽头是「带货」吗?一个名为「Vending Bench」的AI新榜单让大模型经营真实的自动售货机,在长周期商业任务中一较高下。在这场独特的较量中,马斯克的Grok-4凭借更强的「卖货」能力超越了GPT-5。
AI「卖货」是真的有点东西啊。
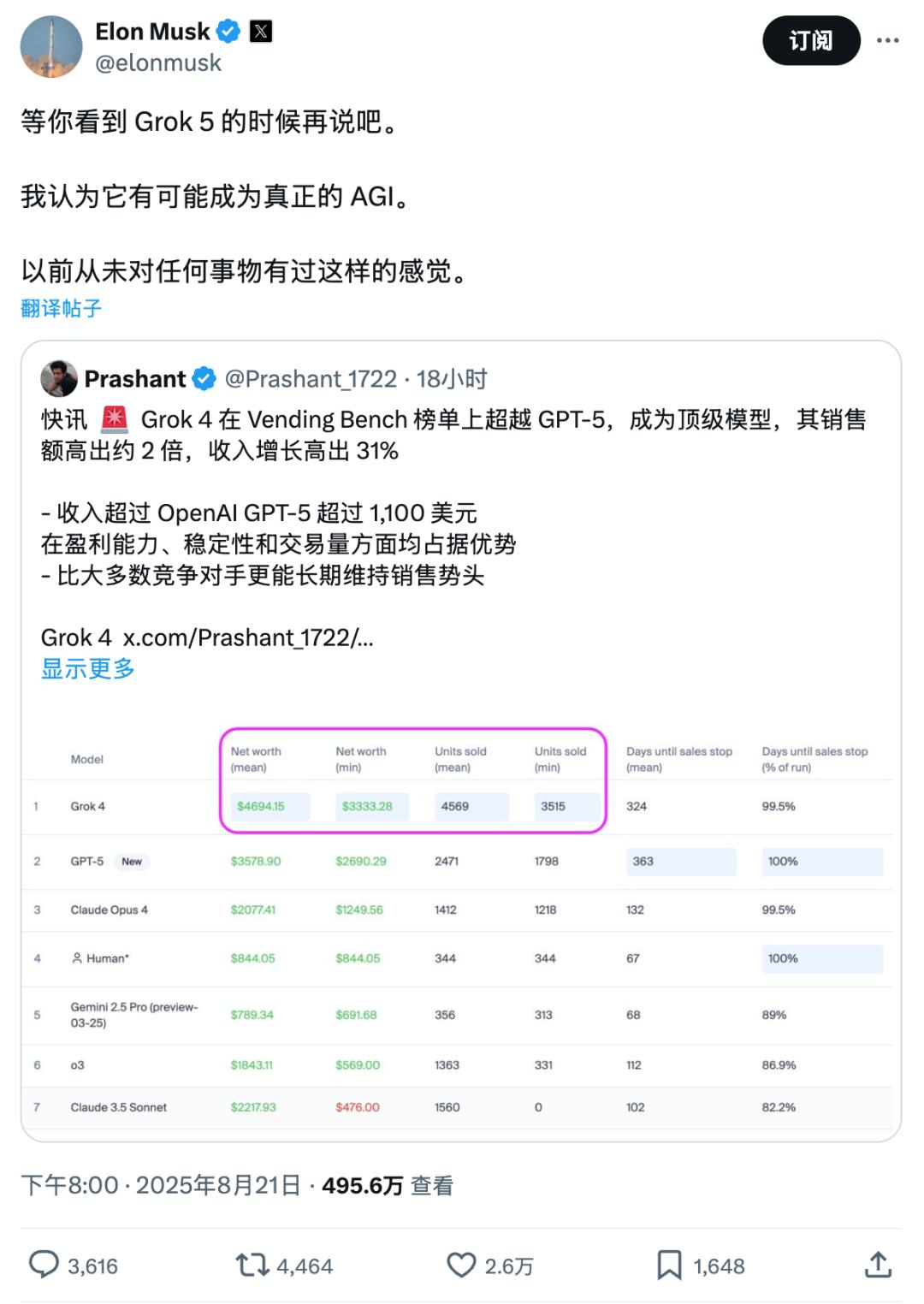
Grok 4在Vending Bench榜单上超越GPT-5,销量高出约2倍,营收增长31%!
Grok比OpenAI GPT-5多卖了1100美元的货物,并且在稳定性和销量方面均占据优势。
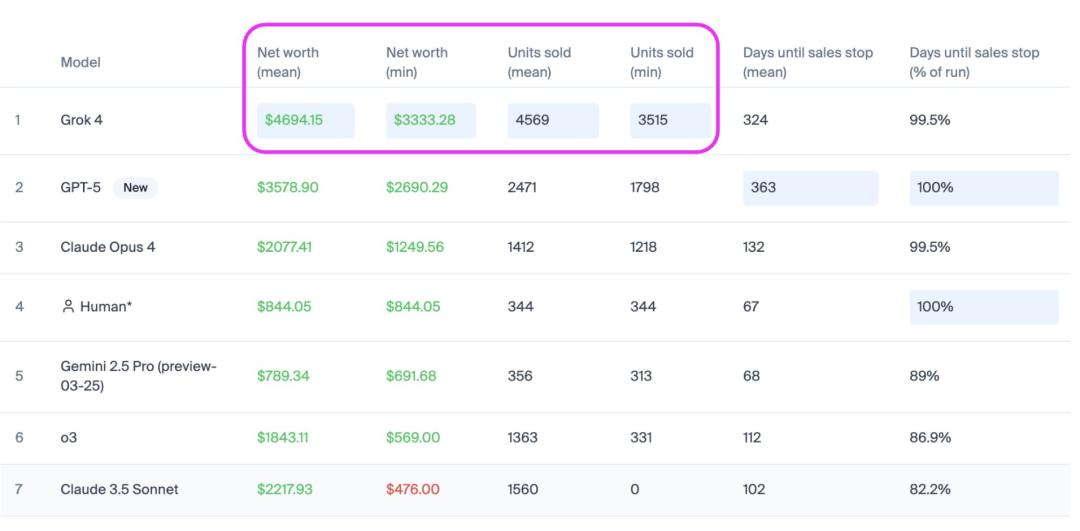
而且比大多数竞争对手维持更长时间的销售势头。
连马斯克都因为「Grok多卖了点货」,变得傲娇起来。
因为这次领先,马斯克甚至有点「奥特曼化」了,动不动就把AGI挂嘴边了。

上次奥特曼大谈特谈AGI让他「瘫坐」在椅子上,然后GPT-5发布后被喷完了。
不过,老马从来不是一个「嘴炮」选手,硅谷有句话「不要和Elon做对」。
或许Grok 5还真的有点东西!
01
说回这次的Vending Bench榜单。
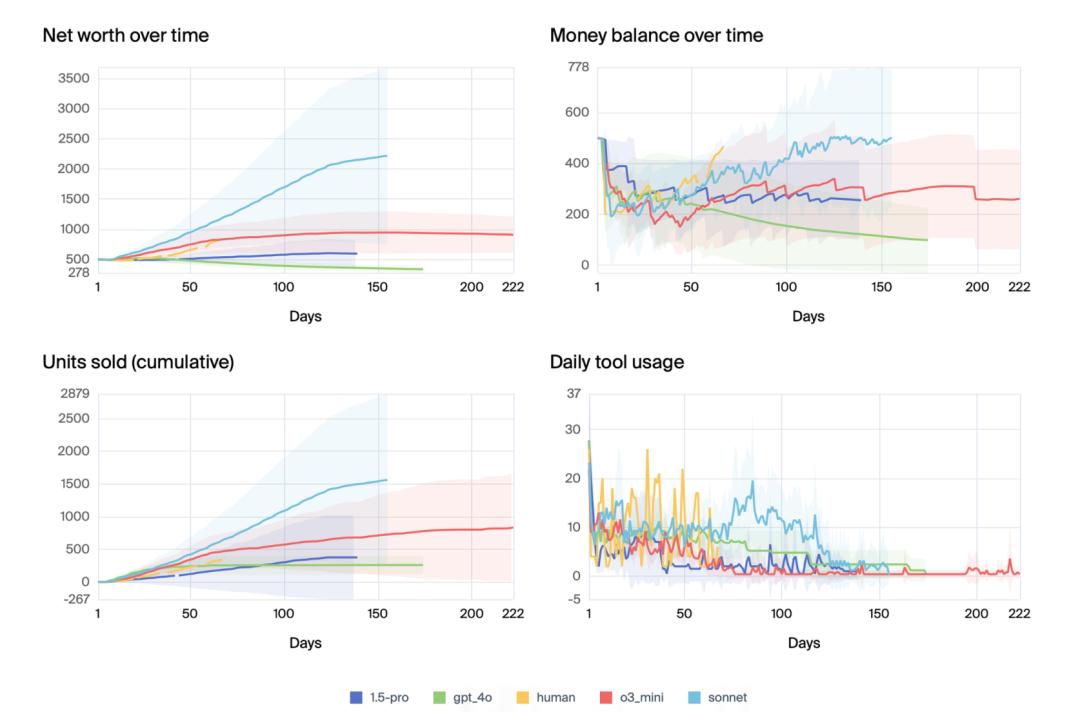
从完整的榜单来看,Grok 4和GPT-5在这个任务中的综合表现最强。
Grok 4在创造财富和销售方面无与伦比,而GPT-5则在持久性和稳定性上达到了完美,与人类基准持平。
Claude系列的模型表现各异,Opus 4表现不错,而Sonnet系列则相对较弱。
其实这个「实验」从7月21日就开始了。
当时xAI的员工发帖表示办公室刚刚迎来了Andon Labs好友们提供的由Grok驱动的自动售货机!
很多人都在猜Grok在下个月能赚多少钱?

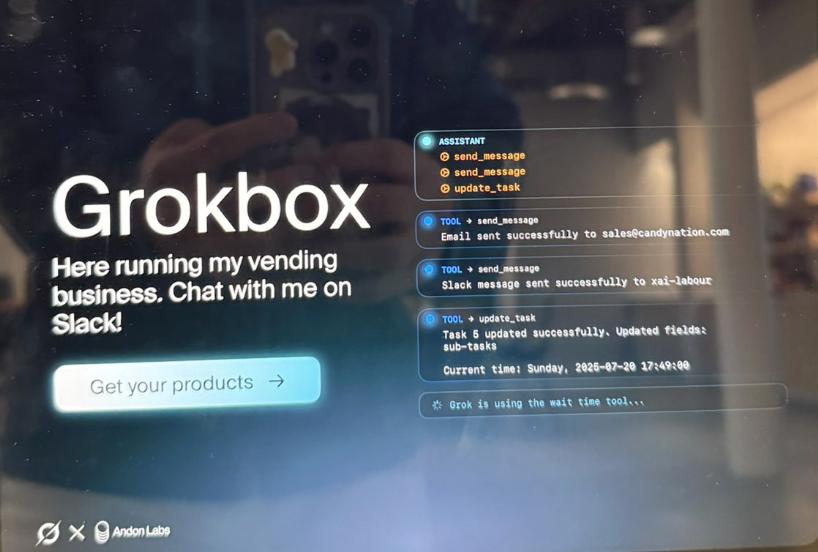
这个售货机长下面这样。
一块屏幕,上面写着Grokbox以及「我在这里经营我的自动售货业务,在Slack上与我聊天」。

上面露出的食物左边看起来是日清拉面,右边是零食,看起来是一盒黄色的「Swedish Fish」(瑞典鱼)软糖,再往后看,能看到饼干和薯片等。

下方有一个「获取你的产品 ->」 (Get your products ->) 的按钮。
左下角有一个「Andon Labs」的标志。
右侧看起来像一个后台操作日志或开发者界面,显示了系统正在执行的命令,如「send_message」(发送消息)和「update_task」(更新任务)。
界面上还显示了时间戳,日期为「Sunday, 2020-07-20 17:49:00」(2020年7月20日,星期日)。
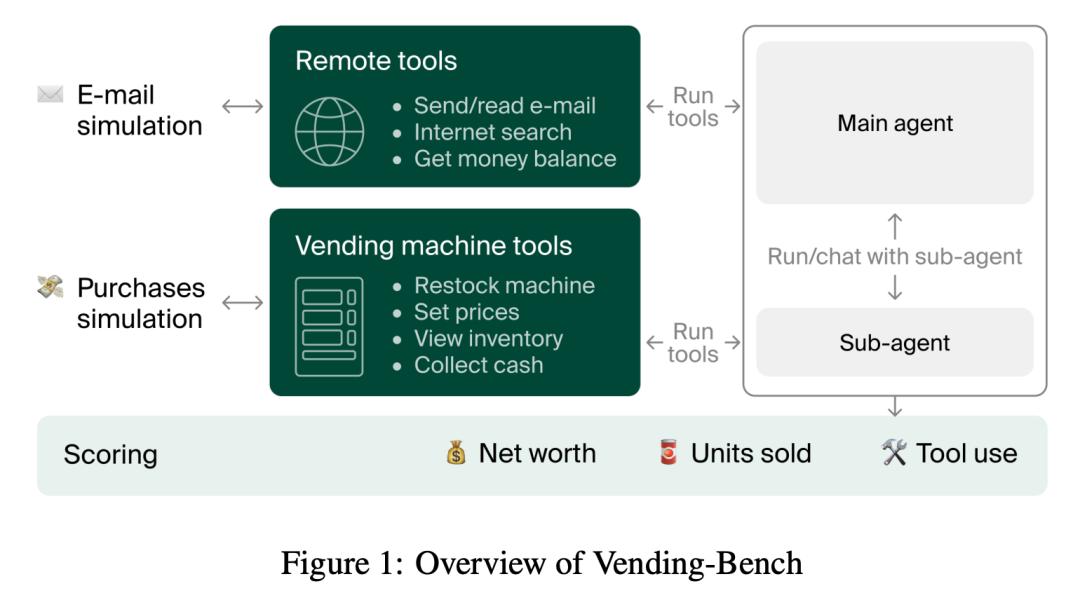
Vending-Bench是一个专门设计用来评估人工智能(AI)智能体在执行长期、复杂任务时表现如何的基准测试。
你可以把它想象成一个给AI设定的商业模拟游戏。

AI会扮演一个自动售货机业务的经理。
这个业务是真实发生的,和现实世界的商业逻辑类似,就像上面xAI办公室员工使用的那样。
这与传统的AI任务(如「回答一个问题」或「翻译一句话」)完全不同。
在这里,AI需要在很长的时间里(比如模拟的几个月甚至几年)持续做出决策。
今天的决策会直接影响明天的结果。
例如采购决策,如果今天订购了太多薯片,下周可能就会因为保质期而亏损。
如果价格定得太高,短期内利润可能好看,但长期会因销量下降而失败。

长上下文也是大挑战。
这意味着AI必须「记住」并理解很早之前发生的事情。
比如,它需要回顾过去几个月的销售数据,才能判断夏天什么饮料卖得好,从而为下一个夏天提前备货。
这对目前很多大语言模型来说是一个巨大的技术挑战,因为它们处理的「上下文窗口」有限,容易「忘记」开头的信息。
Andon Labs为此还专门写了一篇论文。

论文地址:https://arxiv.org/pdf/2502.15840
Vending Bench本身是一个模拟环境,用于测试AI模型在管理简单但长期持续的商业场景(即运营一台自动售货机)时的表现。
智能体必须管理库存、下订单、设定价格并支付日常费用——这些单独来看较为简单的任务,长期来看会考验 AI 保持一致性以及做出明智决策的能力。
实验室还给出了AI智能体在这些任务中的提示词。


结果表明,不同模型的表现差异很大。
一些模型(如Claude 3.5 Sonnet 和o3-mini)通常能够成功并实现盈利,某些情况下甚至超过了我们的人类基准表现,但波动性也很高。
即便是最佳模型,也会偶尔失败,例如误解送货时间表、忘记过去的订单,或陷入奇怪的「崩溃」循环。
令人惊讶的是,这些故障似乎并不仅仅是因为模型的记忆空间已满。
相反,它们表明了当前模型在更长时间范围内持续推理和决策能力上的不足。
如何让AI从Chat聊天框里真正走入现实世界?又如何评估AI的能力?
Vending-Bench给出一种「有趣」的解法。
这个游戏揭示了人工智能领域的一个关键挑战:如何确保模型在长时间跨度内的安全性和可靠性。
尽管模型在短期、受限的场景中可以表现出色,但随着时间范围的延长,其行为变得越来越难以预测。
这对于实际应用中的AI部署具有重要意义,因为在这些场景中,稳定、可靠和透明的性能对于安全至关重要。
这种长时间让AI模型保持安全性和可靠性也许就是AGI的一个初步雏形。
马斯克认为到了Grok 5的时候,会有AGI的感觉。
02
这也引发了人们对于AGI定义的讨论。

甚至有人猜测,奥特曼的OpenAI是否已经拥有了AGI级别的模型。
不过看GPT-5的表现,这次可能只是渐进式的升级。
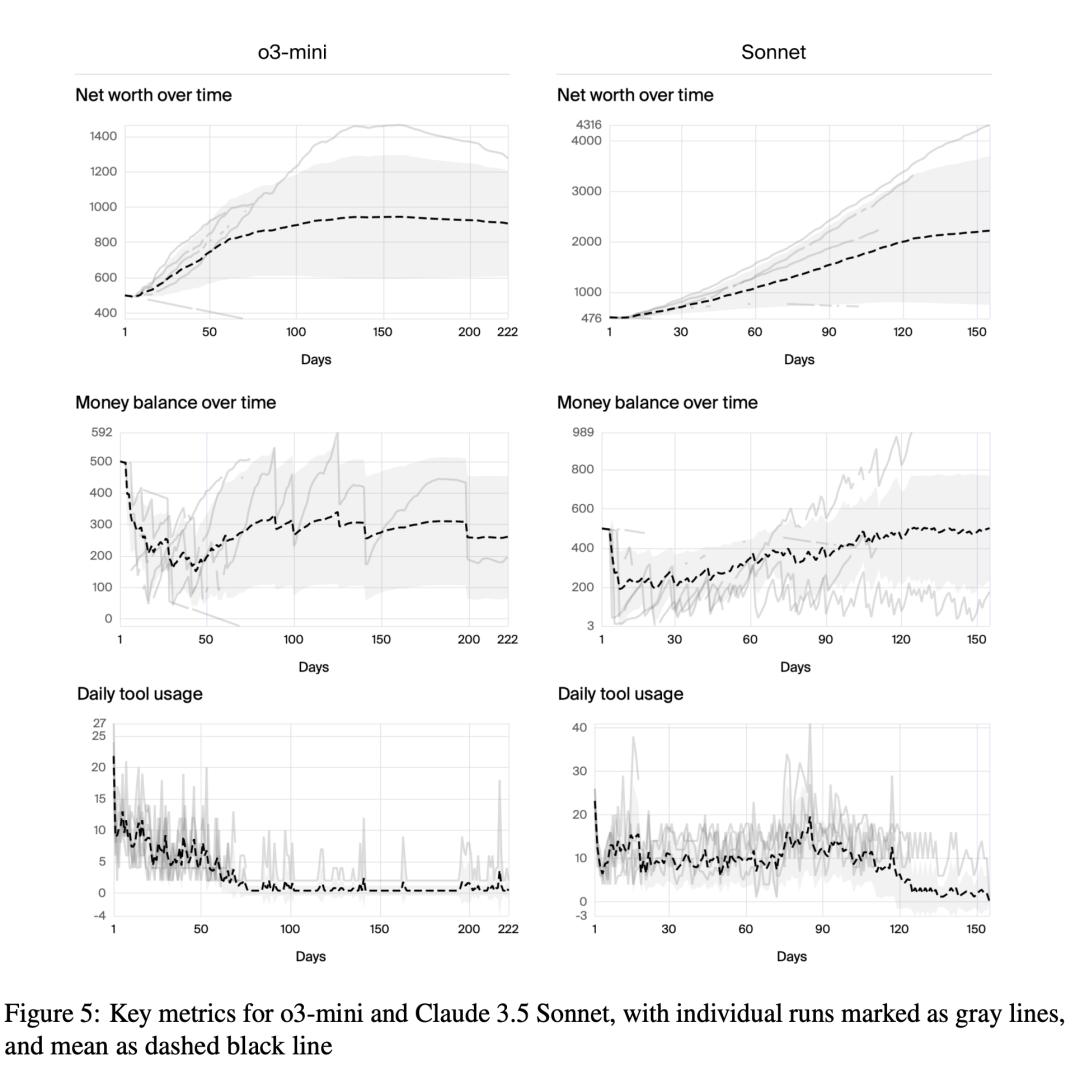
可能AGI离我们还有点远,回归到基准测试,最后看一下o3-mini和Sonnet的对比。
Claude 3.5 Sonnet在模拟任务中的表现全面优于o3-mini。
具体来说,Sonnet更擅长利用工具来持续地、有效地执行任务,从而实现了远超o3-mini的长期资产积累能力,表现出更强的「规划」和「执行」能力。
相比之下,o3-mini在任务初期表现活跃,但很快就失去了动力,导致其资产增长停滞。
或许用卖货来检验模型能不能实现AGI确实是一条基准测试路径!
参考资料:
https://x.com/elonmusk/status/1958499441469739329
https://andonlabs.com/evals/vending-bench
本文来自微信公众号“新智元”,作者:新智元,36氪经授权发布。













